Two Independently Iterative Pipelines
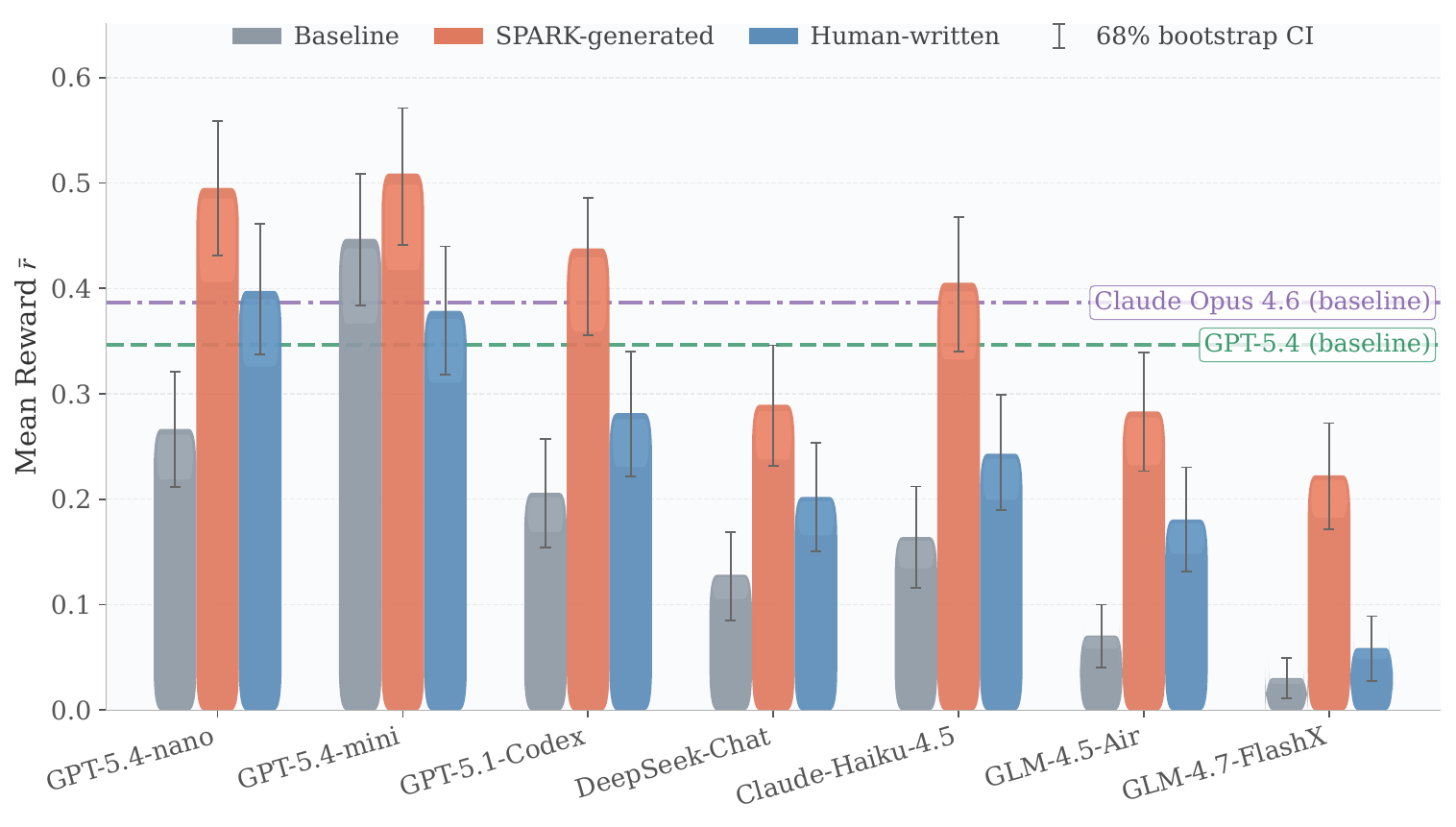
SPARK decouples task construction from skill generation into two pipelines that can evolve independently: tasks can be expanded continuously, while skills are repeatedly distilled from verified trajectories without manually authoring both sides.
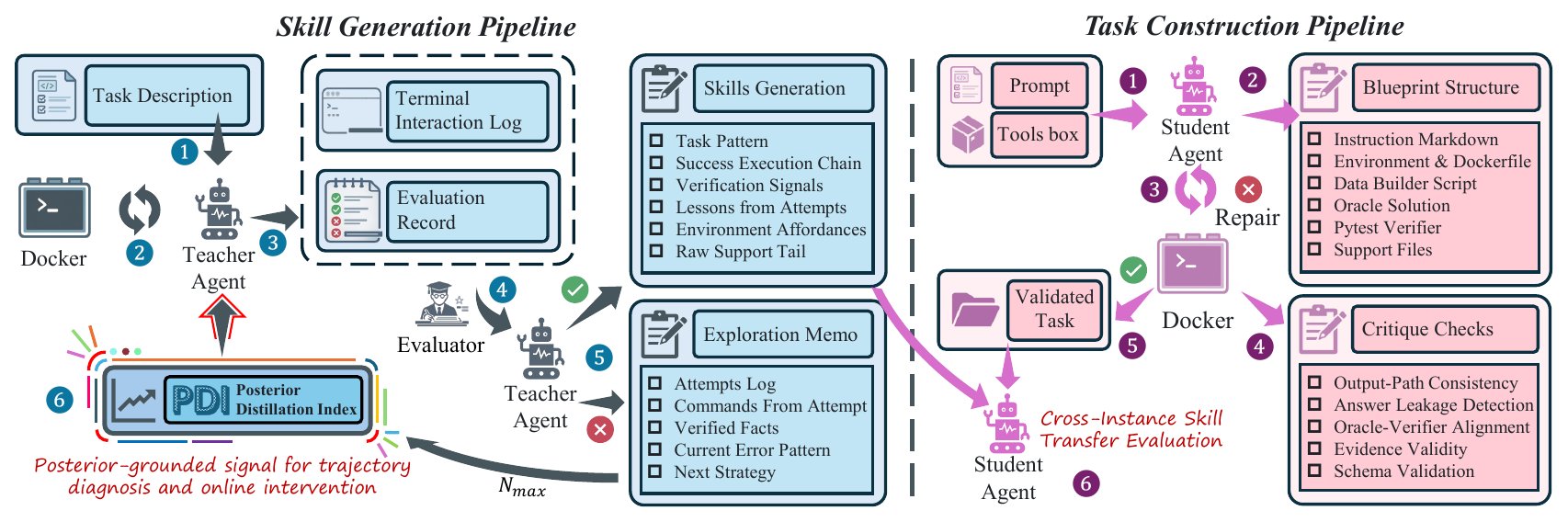
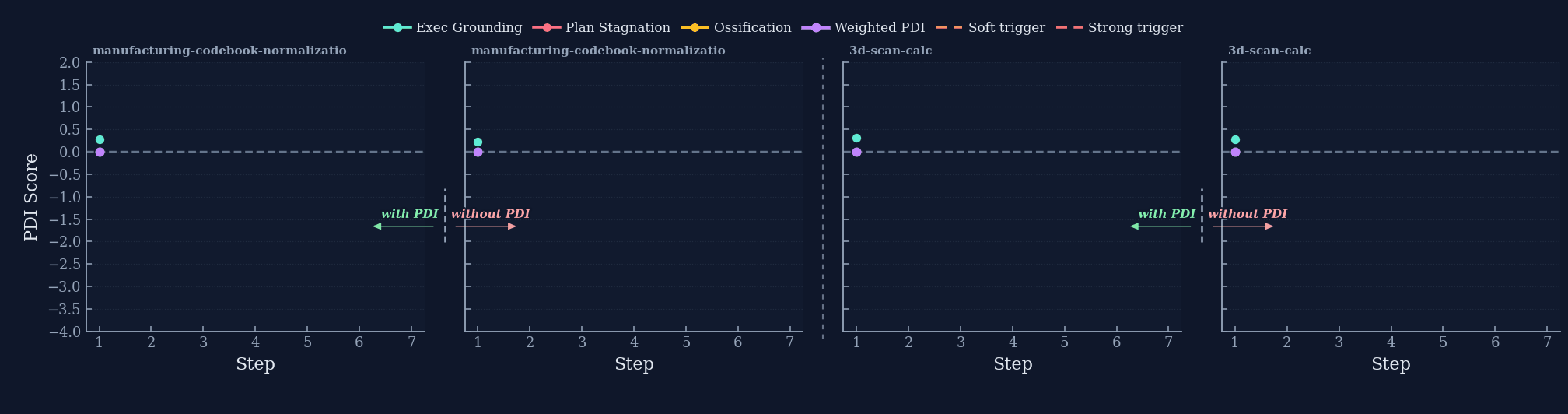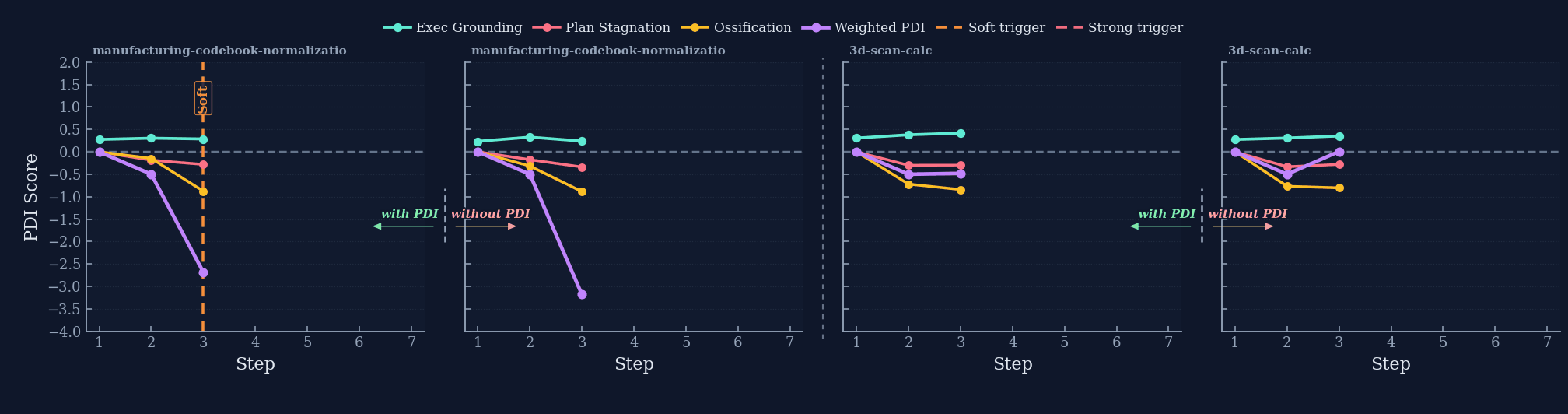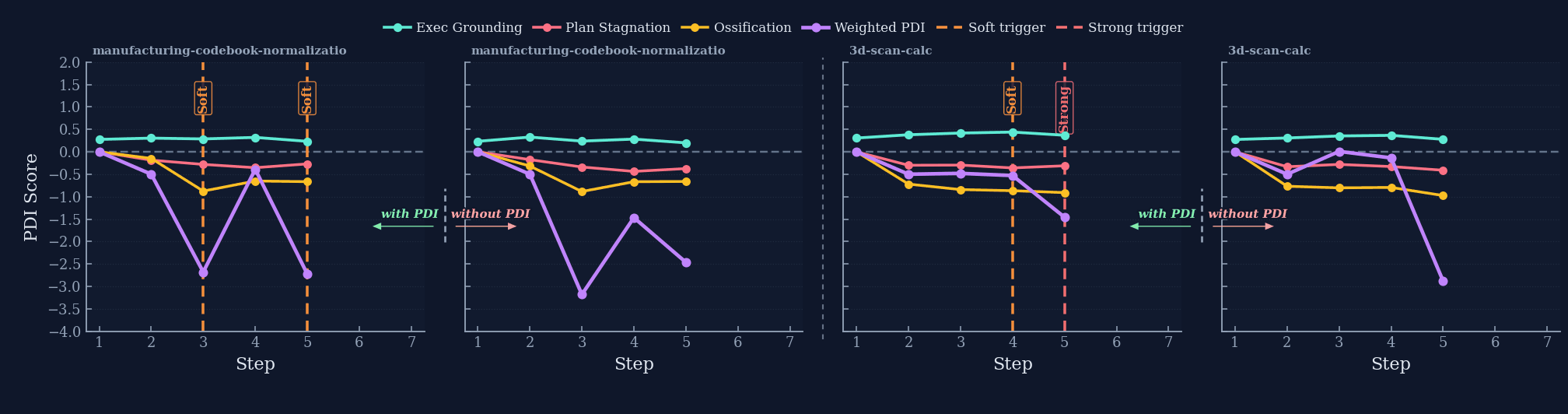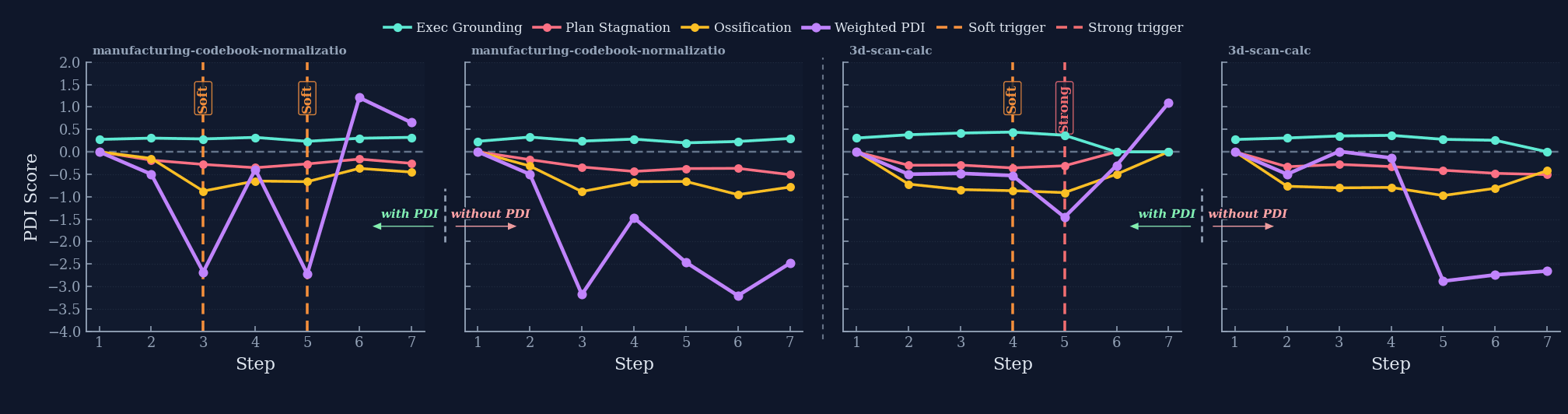
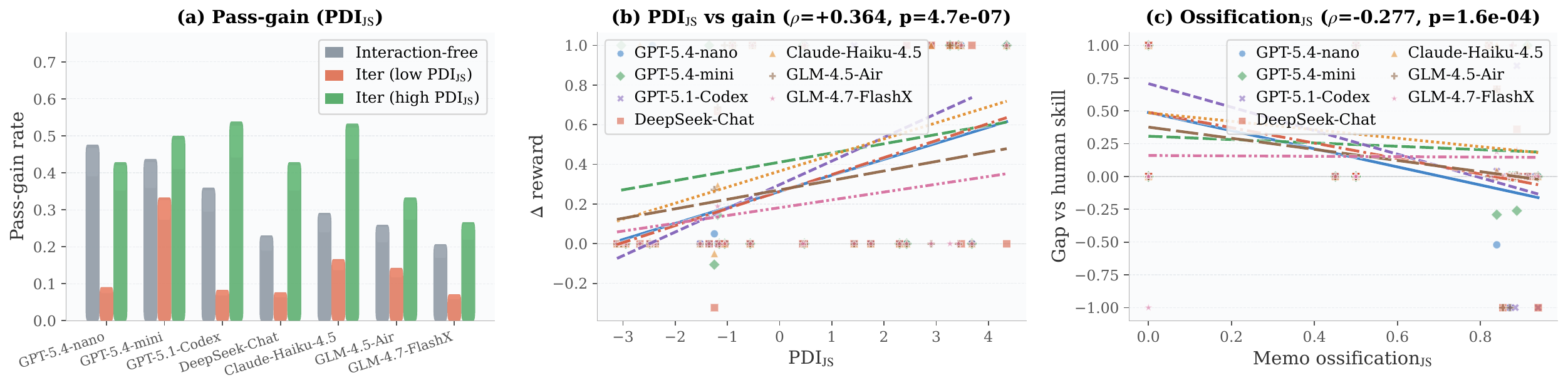
SKILL.md upon success, and receives targeted PDI-proxy interventions upon failure.
Right: Task Construction. Blueprint generation → repair → critique → oracle validation converts prompts into executable benchmark instances;
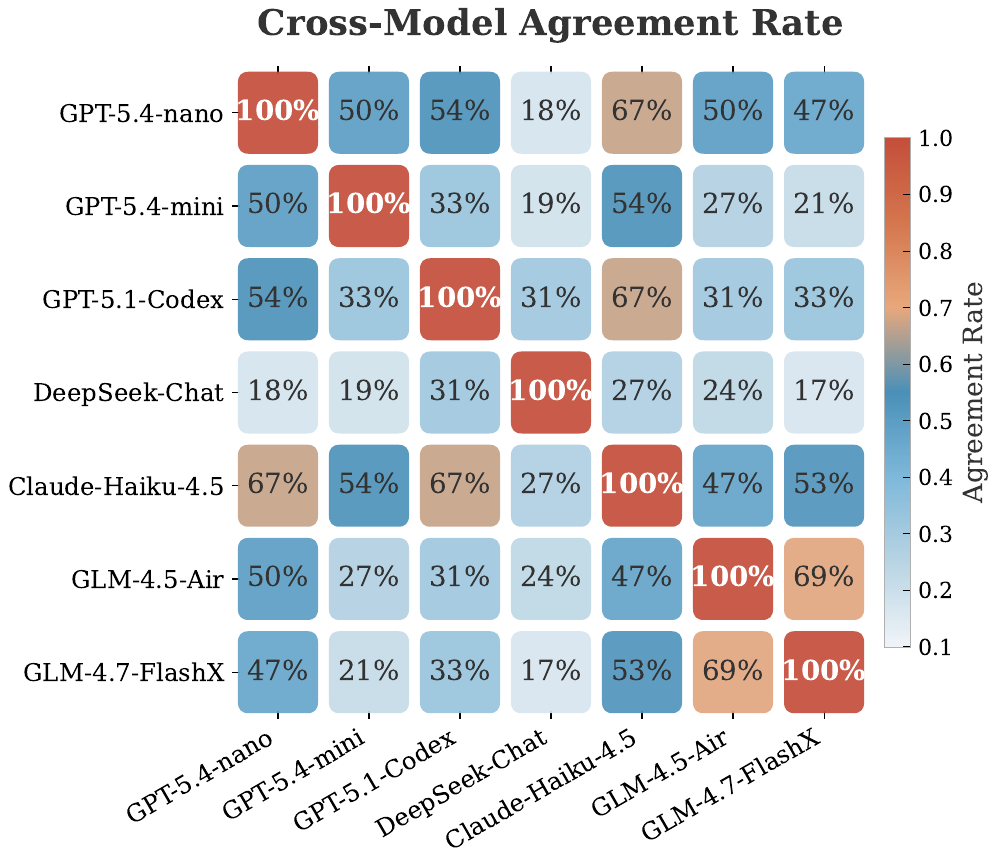
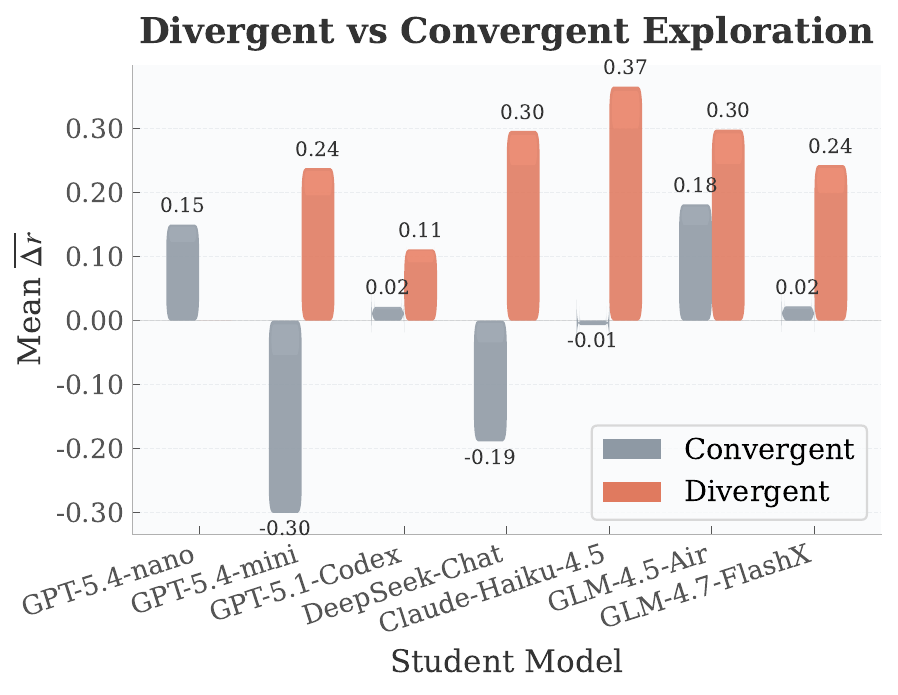
student agents then evaluate whether PDI-grounded knowledge transfers across tasks rather than overfitting to the teacher’s original trajectory.
🔁 Skill Pipeline
execute → judge → summarize → retry → distill skill
- Attempt log: a one-line summary of each attempt, preserving both strategy and outcome.
- Verified Facts: environment-confirmed facts that persist across memo rewrites.
- Current Error Pattern: the active diagnosis of the current failure mode.
- Next Strategy: a plan that must differ from all previous attempts.
- Commands: the key shell actions from the previous attempt.
The memo is rewritten as a whole rather than appended to, preventing the context from being flooded with low-value stdout; historical versions are still retained so cross-attempt patterns remain analyzable.
🧩 Task Pipeline
prompt → retrieval → TaskBlueprint → Harbor task → oracle validation
- Blueprint: structures a natural-language prompt into instructions, environment, support files, oracle, and verifier.
- Repair: iteratively fixes constraint violations in the blueprint.
- Critique: checks semantic consistency and executable constraints.
- Validation: accepts only tasks that pass a deterministic oracle.
This is a build-and-verify process rather than a one-shot LLM generation step. It also enables batch generation of unseen instances from the same problem class, testing whether a skill captures reusable procedural structure.