27 Real Servers · 200+ Tools
All servers are booted over stdio through a single
MCPHost. The agent sees a unified catalog and picks
relevant tools at each step. The figure counts tools per server in the
current fleet.
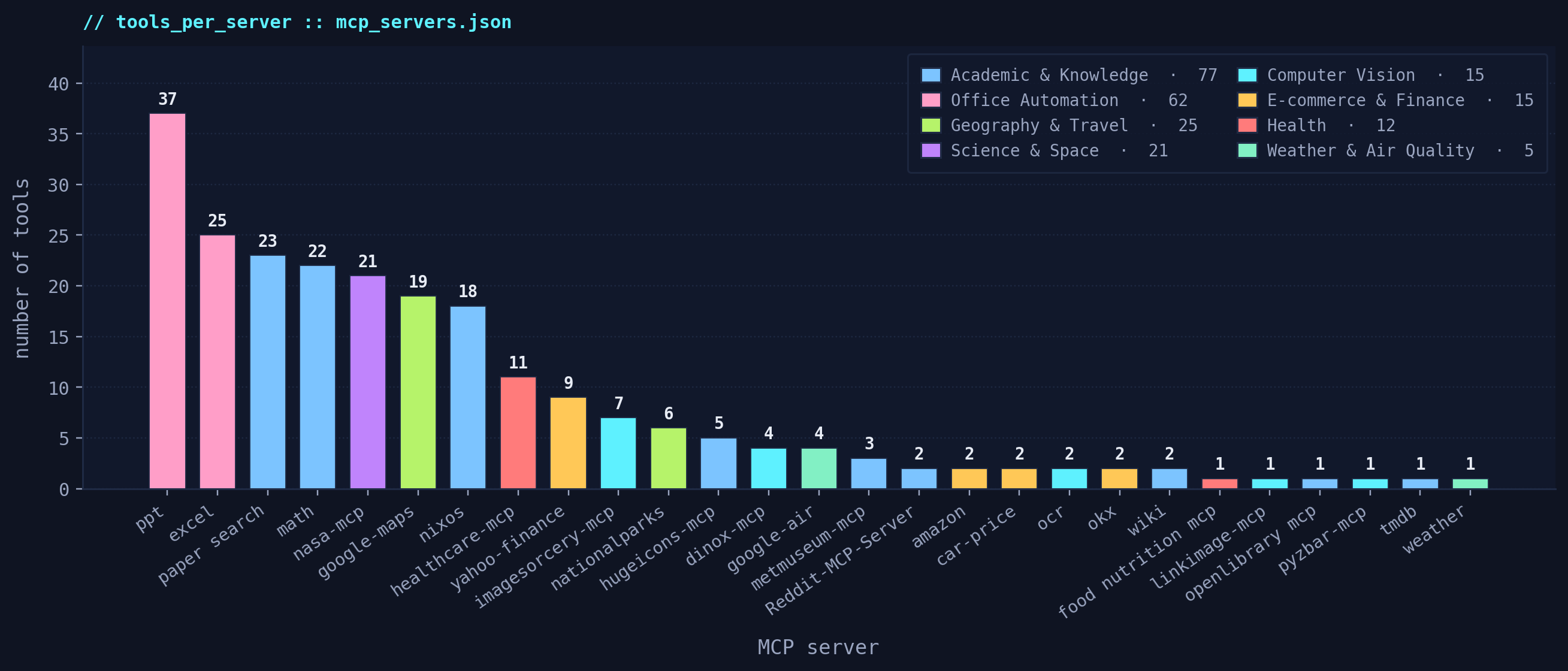
~ knowledge
wiki · openlibrary · paper_search (arXiv / PubMed / bioRxiv / medRxiv / IACR / Semantic Scholar) · nixos · metmuseum · nationalparks.
~ vision
ocr · pyzbar (barcodes) · imagesorcery (crop/draw/blur) · mcp-yolo (Ultralytics YOLO + YOLO-World) · linkimage.
~ commerce
amazon · tmdb · hugeicons · car-price (FIPE).
~ finance
yahoo-finance · okx (crypto prices + candlesticks).
~ location
google-maps · google-air · weather · nasa-mcp.
~ health / food
healthcare-mcp (FDA / PubMed / Clinical Trials / DICOM) · food_nutrition_mcp.
~ office
excel · ppt (Office-PowerPoint-MCP-Server).
~ math
arithmetic · stats · trig — closes the numeric reasoning loop.
~ social
reddit (subreddit search, posts, comments).